When AI Companies Piss Off the Record Industry
Notoriously, not a good enemy to have.

This week, we’re talking:
RIAA, Universal, Warner and Sony’s landmark lawsuit against Suno and Udio — perhaps getting one step closer to an answer RE: does model training fall under fair use? 🎶 🏴☠️
APRA is heading to markup — can it survive being watered down? 🇺🇸 🗂️
Changing privacy policies in the dead of night is always a bad idea — whether or not regulators will make you pay for it is another question. 🌙 📃
Opting out of META’s machine learning training is hard on purpose. 💬 👀
Gamification was all the rage — did it hurt us more than help us? 🎮🕹️👾
Toys ‘R’ Us and that ad. 🧸❤️ 🤖

My Take:
In today’s batshit example of “training my model is just fair use” insanity, I give you AI Music companies Suno and Udio. Both were just hit with a lawsuit spearheaded by RIAA, Universal, Warner and Sony alleging the infringement of copyrighted music “at an almost unimaginable scale.” The last time the record industry took up arms in this way, Napster and every company in its cohort were sued into oblivion and ultimately ceased to exist.
For their part, Suno and Udio aren’t exactly running from the allegations. In a Rolling Stone profile of Suno published in March, investor Antonio Rodriguez all but acknowledged that they were playing fast and loose with copyrighted material. He understood when he invested that a lawsuit was likely coming but saw that as just the cost of doing business. He even went so far as to say that he wanted it that way. “Honestly, if we had deals with labels when this company got started, I probably wouldn’t have invested in it. I think that they needed to make this product without the constraints.” I don’t think the word “constraints” has ever done quite so much heavy lifting.

I believe that music is primal and distinctly human. I’m all about putting the machines to work, but only in the service of musicians and people who love music — and not the other way around.
That’s why Boombox exists. We’re a team OF musicians who want to use AI to streamline the monotonous, boring tasks that go into music creation and to make music collaboration cooler, faster, and better.
And that’s why we’ve created Boombot, your AI assistant producer. We built Boombot with the belief that AI should augment musical artistry, not replace it -- and certainly never steal or “borrow” from it. Boombot is trained on AI infrastructure using ethically-sourced data only. It does not, nor will it ever, train on the intellectual property of Boombox users or any other musician's art.
It’s just another reminder that AI — like any other tool — can be used in the service of human flourishing, or it can deplete and degrade human experience. Though with all these bad actors, musicians could easily be forgiven for losing sight of that.
Stories I’m Following:
Federal privacy law faces new hurdles ahead of markup by Tim Starks VIA CyberScoop 🇺🇸 🗂️
Tomorrow is a big day in data privacy land as the APRA (federal privacy bill) goes to markup. 72% of US adults say they want the bill but it is already getting watered down. The latest version of the bill ditches protections against data-driven discrimination and bias in AI. Big Tech is arguing that AI is separate from data privacy… and if you buy that, I’ve got some ocean-front property to sell you in Arizona.
When the Terms of Service Change to Make Way for A.I. Training by Eli Tan VIA NYTimes 🌙 📃
I’ve written before about the tendency of large companies to change their privacy policies quietly (👋 Adobe) and cross their fingers that consumers don’t notice. This — and the story below — really come down to the fact that machine learning has exhausted most publicly available data and remains hungry for more. The FTC has already informed tech companies that changing privacy policies to scrape old data “could be an unfair or deceptive” practice. It seems that Big Tech companies missed the memo. Whether or not regulators will act remains to be seen.
What I’m Reading:
How to opt out of Meta’s AI training by Melissa Heikkiläarchive VIA MIT Technology Review 💬 👀
I’ve never had a Facebook or Instagram account and I’m increasingly grateful for that. For everybody else in the world, your privacy is under attack. Starting TODAY, META can use your data to train its AI models. It’s a sneaky invasion of privacy — and a good reminder of why deceptive patterns are increasingly referred to as “privacy Zuckering.” The cumbersome process to opt out of this violation is outlined at the link above.

How gamification took over the world by Bryan Gardiner VIA MIT Technology Review 🎮🕹️👾
A long read but a must read, nonetheless. Gardiner’s piece poses the question: Gamification was always just behaviorism dressed up in pixels and point systems. Why did we fall for it? The Tl;dr is this: “Instead of liberating us, gamification turned out to be just another tool for coercion, distraction, and control.”
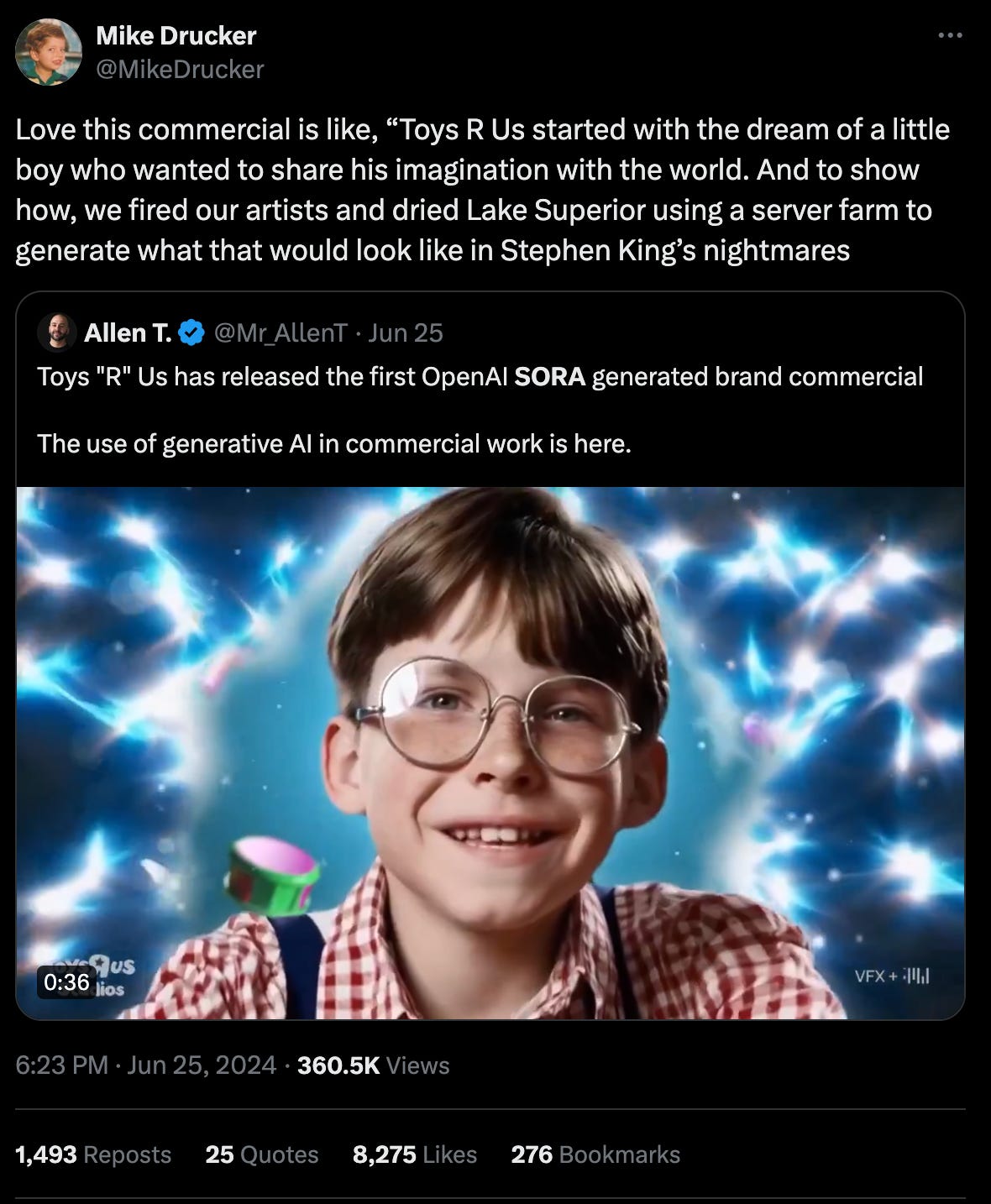
Toys 'R' Us uses OpenAI's Sora to make a brand film about its origin story and it’s horrifying by Danny Gallagher VIA Engadget 🧸❤️ 🤖
This is a PR stunt but even stunts can be better executed. Lots more thoughts here but they’re perhaps best summed up by comedian, Mike Drucker.